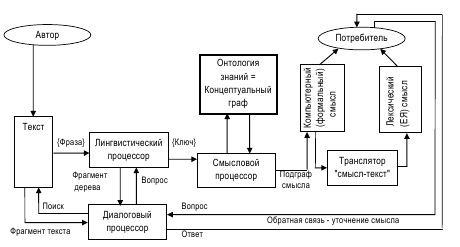
На помощь в определении понятия «смысл» приходит онтология ИО*3.
Идея состоит в том, что если «пропустить» текст через онтологию, которая является структурой знаний,
то на выходе получим концентрированное знание, которое коррелирует с текстом. Концептуальный
фильтр онтологии даст на выходе концептуальный, или онтологический смысл.
В работе [Святогор и Гладун, 2009] приводится формальное определение «онтологического смысла»;
здесь оно повторяется тезисно.
Задан концептуальный онтологический граф ИО*3.
Элементарный смысл определяется как пара соединённых соседних узлов онтологического графа.
Связи не обязательно именуются, они могут лишь фиксировать факт некоторого взаимодействия двух
слов (например, ворона–птица, пассажир–самолёт, развитие–прогресс). Онто-граф состоит из
множества связанных между собою элементарных смыслов, которые вступают в дозволенные
комбинации. Связная часть онто-графа, соединяющая два удалённых узла, образует подграф; при
изменении в нём стрелок на противоположные (снизу – вверх) получается цепочка подграфа.
Цепочка связанных элементарных смыслов, которая начинается в некотором «активном» узле и
заканчивается в вершине онтологии, образует онтологическую цепочку активного узла. Цепочка,
выделяемая активным узлом на онтологическом графе, трактуется как смысловая траектория и
называется онтологическим смыслом активного слова.
Комментарий. Процесс возбуждения смысловой траектории начинается с того, что в предложении из
ядерной конструкции выделяется некоторое «ключевое слово». Если оно присутствует в онтологическом
графе, то активное слово возбуждает соседний концепт, возбуждение передаётся дальше на высшие
уровни онтологии – вплоть до вершины пирамиды. Результатом процесса является цепочка, то есть –
дискретная упорядоченная последовательность взаимосвязанных концептов; она является
формальным онтологическим смыслом входного слова в заданной «картине знаний».
Пример. В ядре предложения выделены ключи: ворона и сыр. Для них будут построены
соответствующие концептуальные цепочки: 1) ворона – Птица – Полёт – Движение – Биосфера –
Жизнь – Материя и 2) сыр – Еда – Жизнь – Материя.
Связи пока-что не интерпретируются – в данной репрезентации онтологического смысла они не имеют
значения: необходимо и достаточно зафиксировать только связь пары объектов. Далее, поскольку
ключи находятся внутри одного предложения, то автоматически будет построена связь, ранее в
онтологии отсутствовавшая: ворона – сыр. В итоге, линейный формат онтологического смысла будет
следующий:
ворона (птица, полёт, движение, биосфера, жизнь, материя) –
– сыр (еда, жизнь, материя).
Семантическое пояснение суммарной цепочки, в случае необходимости, может быть дано позже, а связи
могут быть интерпретированы повторным обращением к тексту (ворона имеет сыр).
В зависимости от целей семантического анализа цепочки можно укорачивать за счёт абстрактных
категорий. Кроме того, цепочки могут быть как линейными, так и разветвлёнными, то есть – с
присоединением узлов, примыкающих к траектории.
Результатом полного просмотра текста является множество – «пучок смысловых траекторий», который
можно трактовать как «семантический портрет текста».
Онтологический смысл может быть целью и результатом семантического анализа ЕЯ текста
благодаря таким свойствам:
– ключевые слова в смысловой цепочке извлекаются непосредственно из текста;